Consensus: A Scalable Interactive Entertainment System
Crosbie Fitch
Pepper’s Ghost Productions
Abstract
The design of a scalable system to support networked, interactive, virtual environments is presented, which forms the basis of work in progress to produce Consensus: an active, object oriented, distributed database, optimized to support simultaneous and interactive exploration of indefinitely large virtual worlds by indefinite numbers of Internet users.
Data comprising objects within the virtual world are continually distributed between computers, not only in order that they may share in simulating the virtual world, but also that they may independently and scalably, model and render scenes in view of virtual characters. Although objects are widely replicated, a single instance will override other instances, effectively providing an arbitration scheme. There is a continuous process of reallocating responsibility for the processing of these arbitrating instances based on which computer is most suited to the task. Computer relationships are continuously revised to optimize the distribution network.
UDP/IP & MBone are used for distributing data. Bandwidth is maximized by accepting any messaging failure and consequential loss in object integrity given that inconsistencies arising are expected to evaporate quickly with frequent updates. This is considered acceptable given the system's intended application to large scale interactive entertainment with its priority of low latency interaction over accuracy.
CR Categories and Subject Descriptors: C.2.4 [Computer-Communication Networks] Distributed Systems - Distributed applications, Distributed databases; D.1.3 [Programming Techniques]: Concurrent Programming - Distributed programming; H.2.4 [Database Management]: Systems - Distributed databases, Object-oriented databases; I.3.7 [Computer Graphics]: Three-Dimensional Graphics and Realism - Virtual reality; I.6.8 [Simulation and Modeling]: Types of Simulation - Distributed.
Additional Keywords and Phrases: Large Scale Interactive Entertainment, Large Scale Virtual Environments (LSVE), Distributed Virtual Environments (DVE), Distributed Interactive Simulation (DIS), Massive Multiplayer Games, Networked Virtual Reality, Active Distributed Object Oriented Databases, Online Entertainment, Computer Supported Collaboration.
1 Introduction
1.1 The Objective
To build the foundations for cyberspace, and to have them last well into the next century, entails the following:
· A system that allows the simulation of indefinitely large scale virtual worlds supporting simultaneous, interactive exploration by indefinitely large numbers of users, e.g. the Internet population.
· A system sufficiently scalable and flexible that its evolutionary development can keep pace with the ever increasing technical capabilities and demands of networks, users, and their equipment.
· Very efficient and highly fault tolerant use of networks such as the Internet.
· Competitive in performance terms with first and second generation systems such as those based on the US Department of Defense's DIS/HLA infrastructure [12].
1.2 The problems
1.2.1 Latency Now and in the Future
With Moore’s law appearing to govern memory/storage, processor power, and bandwidth, and Parkinson’s law appearing to govern users, traffic, and application size and complexity, one can also observe that latency appears to obey the same law that governs average city traffic speeds, and perhaps from this, one should estimate a worst case scenario where we can expect no significant improvement in latency for years to come, just as there has been no significant improvement in London (UK) average traffic speeds over the last two centuries, nor any foreseeable [6].
1.2.2 The Need for Scale
The best demonstration of the attraction of large scale virtual worlds, is the real world. A virtual world that approaches the depth and size of the real one is likely to be similarly popular. The best virtual worlds will offer players large amounts of freedom and provide attractive opportunities, to explore, create and interact. Large scale means a scaling by the same order of magnitude as the number of users with Internet connections.
1.2.3 Challenges of Scale
A large scale virtual world will be too big to launch in one go, too big to shut down or recall, and too big to develop wholesale. The entire system must support live content development, live update, and uncoordinated system upgrade. There can be no bottlenecks and scalability is required at all levels: from 4 to 4 billion.
We need a simple design, such as a distributed system based on modular system components (supporting piecemeal development), and all on an affordable budget.
1.3 The Solution
Opportunities for solutions to these problems naturally lie across a variety of areas. Improvements can be made at the network level, e.g. the transport layer taking responsibility for determining the best way to deliver messages (whether multicast via wire, or broadcast via satellite). Improvements can also be made at the rendering end, e.g. texture and geometry compression may well result in lower bandwidth consumption and storage overhead. However, the only areas addressed in this paper are the application, the scene modeler, and the world simulation. The Consensus system is only concerned with the last of these, as it is the key area in which a scalable system must focus its energies. Any improvement in any other area will only contribute positively to the performance of the overall system.
Let us first briefly touch upon the need to realize that applications cannot be designed without consideration to latency, and then highlight the way the virtual world is presented to a user via an intermediate scene model and why this should be separate from (and only needs to be an interpretation of) the model used by the world simulation.
1.3.1 Application Design Strategies
Until we discover instantaneous communication, latency (including jitter) will always be a factor in networked applications. This means that whatever tricks an underlying system can perform or facilitate, the application must still take a large part of the burden of ameliorating the effects of latency.
Application-side approaches to latency are relatively well known, so here is a rather brief list:
1. Separation Do not map player controls to an avatar
2. Incorporation Build delay into controlled objects (inertia, arming period, etc.)
3. Prediction If it can be predicted, it doesn’t need communication
4. Explanation Depiction of mist, deafness, indecision, etc.
5. Delegation Employ AI avatars or other players to act remotely
6. Avoidance Don’t let distant players meet
7. Planning Communicate future changes before they are to happen
8. Hiding Produce feedback from accumulation of actions rather than each one
If the application is to play its part in ameliorating latency, whatever underlying system is used must present enough information and facilities for the application to achieve this. However, this must not be in such a complex manner that an application programmer has as hard a task as the systems programmer. This tends to indicate that the underlying system should appear as transparent as possible, i.e. applications may be implemented as though destined for a single user system, but facilities are provided to program latency ameliorating strategies in relatively high level terms (where default behavior is inadequate).
1.3.2 Scene Independence
Before going any further, we should be careful to delimit the task of this networked system: it is only concerned with simulating a virtual world and presenting this consistently to an indefinite number of computers. As can now be explained, we reduce the communication volume considerably if we restrict ourselves solely to simulation of the essential and salient features of this virtual world.
Although most will be familiar with the benefit of separating appearance from behavior (texture and geometry separate from object, identifier and attributes, velocity say), this separation can be extended further and perhaps subtly so. The scene is only necessary for the user to sense and interpret the virtual world, and it may well have far greater fidelity. The virtual world need only be described in quite high level (and thus concise) terms, e.g. 'An aircraft carrier at sea on a stormy evening, bearing NW, at 15 knots, etc.'. As long as a scene modeler can interpret this description into a high fidelity, local simulation then it doesn't really matter if different users have slightly different textures, geometry, telemetry, or fluids and physics models, etc. Their verbal descriptions of the scene will still agree.
While, across poor communication links the Consensus system may provide a rough and jerky sketch of the world, it will at least be universally consistent. It is the scene modeler's job to present this as elaborately as system resources allow and with as few discontinuities as possible. Though it may be as simple as depicting a corresponding portion of the world model verbatim, separately modeling the scene allows future scaling of this process without requiring the simulation fidelity to scale.
1.4 The Consensus System
Some discussion now follows of the guiding principles and reasoning behind the design of the Consensus system.
1.4.1 Basis
The basis upon which Consensus has been designed is to assume that latency will not change, whereas all other capabilities although restricted, will increase.
Starting with the notion of unlimited storage, processing, bandwidth, and zero latency, any solution is possible, e.g. brute force client/server. The moment you introduce significant latency, all solutions gravitate towards a requirement to cache information and perform local modeling (if only predictive computation). This seems to strongly favor a distributed system solution. Of course, given that storage, processing, and bandwidth are also limited, these need to be utilized efficiently as well.
1.4.2 Latency Amelioration
Here are some of the guiding principles adopted in Consensus:
· Minimize transmission, no guarantees for message ordering, no message recovery
· Communicate high level information first; detailed, lower level information last
· Communicate important information first, unimportant last
· Cache as much as possible (duplicate data)
· Predict as much as possible (duplicate modeling)
· Model the most critical objects often; least critical, least often
· Favor communication with peers having similar interests
· Prefer communication with closest equivalent peers (minimize network distance)
· Keep variable data closest to those that change it the most
· Take advantage of network broadcast facilities, e.g. MBone
· Make the system flexible, allow it to dynamically reconfigure as its nodes change (or fail)
· Continue to design applications with latency in mind
1.4.3 Dedication
It is important to keep the system focused on its objective and avoid taking advantage of its facilities for ancillary tasks. So Consensus is singularly concerned with the need to model the virtual world and makes no attempt to model aspects of the real world, i.e. user parameters, administration, or software configuration. So, in the same way that there is a separation of the scene from the world, so there is a separation of the virtual world from the real one.
1.4.4 Fault Tolerance
It's a dangerous and unpredictable world out there, and the Internet is no different. Any system, particularly a distributed one, must be highly fault tolerant.
· Entire system based on uncertain, best effort delivery (UDP)
· Latest data is more important than reconstructing message ordering, i.e. the more rapidly state is updated the sooner artifacts will evaporate.
· Disconnection is likely, data corruption is probable
· All nodes are subject to failure, all nodes must be fault tolerant
· Continue in the face of catastrophe
· Continuous monitoring of local system integrity (primary security measure)
· This is entertainment – perfect replication and consistency is not necessary
2 RELATED WORK
2.1 Systems in Production
There are various companies, network, and premium service providers, such as TEN[1], MPATH[2], Wireplay[3] [17], that provide network and/or software platforms that facilitate and improve multi-user 3D games (among other things). However, they appear focused on the current and immediately forthcoming market for small to large (10-1,000) multi-player 3D games as opposed to truly scalable systems.
The US Department of Defense is probably the most successful pioneer of distributed interactive simulation systems, notably its SIMNET [4] system, its DIS and HLA protocols [12], especially in terms of working product. However, as one might suspect, these require considerable development resources and high performance systems in order to be used effectively. In addressing such concerns, DIS-Lite [19] has been developed. Although, a promising candidate for the next generation of large scale interactive entertainment, DIS-Lite still places a large burden on the applications developer in terms of the level of awareness they must have concerning the intrinsic problems of distributed interactive simulation. That Consensus recreates the single user 'game engine', but in a transparently distributed form, should give it an advantage in this respect.
2.2 Distributed Systems
There are a variety of distributed system approaches to the development of large scale virtual environments and Consensus is no stranger to many of the techniques they use. Probably most similar to SPLINE [1], especially in its aims to be scalable, Consensus goes further in supporting multiple worlds and having a more general and dynamic solution to the problem of managing communication and interest relationships between objects than SPLINE's Locales and Beacons [2].
Repo [13] and COTERIE [15] are other excellent systems from which to explore this field further. Based on these, Repo-3D [14] is a fairly recent application of a distributed system approach to the task of replicating a 3D scene (especially an Inventor style scene graph). In contrast to this, Consensus only focuses upon the larger problem of distributing a virtual world. The presentation of the scene then represents a small portion of the task, and so, instead of attempting to replicate the scene as in Repo-3D, Consensus deliberately abdicates responsibility, allowing a scenic interpretation of replicated application state to be freely represented (by a separate client-side, scene modeling system).
Furthermore, in order to obtain maximum performance, as is inevitably required by developers of interactive entertainment, Consensus has been designed and developed from the ground up. Primarily targeting Windows based systems, it uses COM [16] for modularization purposes rather than Modula 3 [8] (C++ is used for implementation). Thus critical features such as those of distribution languages such as Obliq [5] and toolkits such as Network Objects [3] are re-implemented - incidentally providing opportunities to streamline the system's implementation.
Consensus can be seen as a distributed system at the extreme end of an integrity/performance graph, i.e. towards low integrity/high performance. This means that Consensus has virtually no guarantees of message sequencing, causality, object integrity, transactional integrity, or even delivery - it is only a 'best effort' system. This need to sacrifice integrity for the sake of performance is also evident in other distributed systems aiming for real-time performance such as DOVRE [18]. As long as the end result tends to be consistent and well behaved, then it should be sufficient for entertainment applications.
In comparison with other research efforts, Consensus is probably best seen as a case study, with the rest of this document describing its design and issues arising out of an attempt to put distributed system theory into practice.
3 System Overview
Consensus is effectively the back-end of the system, containing and simulating models of a variety of virtual worlds (or universes). Communicating with this is the Scene Modeler application which expresses interest in, and effectively attaches itself to, an avatar within the virtual world. The Scene Modeler consequently also has an interest in what this avatar can sense (or affect) and interprets this into a presentation to the user via a 3D renderer, audio and other devices. Conversely, the Scene Modeler also conveys the user's input (commands, control manipulations, etc.) to the representation of the avatar, and via this to the avatar itself. There is a separate administration system (Figure 1).
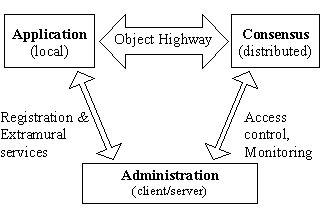
Figure 1: Local application interacts with distributed database, both administered using client/server system.
3.1 Scene Modeler
For one or more Consensus worlds, there may be one or more scene modelers (or other applications) that understand and may interact with them. To interact with a virtual world requires special knowledge of it, and of various classes and objects composing it that are designed for interaction by a scene modeler.
The scene modeler is well suited to an implementation based on a variety of next generation game engines such as Motion Factory's Motivate product [11].
3.2 Consensus - Distributed Simulation
Consensus shares the burden of simulating one or more virtual worlds between all participating computers, each of which is fundamentally a peer, yet also observes a dynamic, hierarchical responsibility structure according to capacity and performance. Thus the task of simulating the virtual world is shared across an interconnected network of computers (nodes of the network), many of which will be those of the participants (users).
Each node has a finite amount of storage in which to store a portion of the data defining the virtual world. Each node strives to contain as much data as possible that is relevant (or potentially so) to its users, prioritizing the most important data. In order to do this, a node will locate nodes that contain the required data and the most up to date versions as possible. Each node therefore continuously changes its relationships so that it communicates directly with other nodes sharing the same interest. Thus each node may serve many other nodes' requests for data, but this is carefully managed so that the communication burden is balanced according to ability.
Ultimately it is the user's avatar expressing the interest, acting as though it is a magnetic force, attracting relevant and interesting data into the local database.
The Consensus system software is comprised of a single set of modules, and this set is duplicated on each participating computer. Every computer shares in all tasks - there is no system whereby some computers are dedicated to one task and others to another. This is because each module is scalable, taking advantage of whatever resources are available. Of course, it may well turn out that some computers with low resources will perform some tasks to a very limited extent, but this division of labor is achieved automatically and continuously. Having a single set of modules makes the entire system much easier to manage.
3.3 System Administration
Some things do require secure, high integrity systems, and systems administration is best suited to these. This component, produced using tried and tested technology, co-ordinates the system software (installation, upgrade, licensing, diagnostics, etc.) and controls user access (lobby service, charging, privileges, etc.).
4 The Project
Consensus is an active, object oriented, distributed database system designed to support massive multi-player games, i.e. large scale interactive entertainment. It is intended to be used in a similar way to a conventional game engine.
The project is currently on hold until such time as funding becomes available to continue. However, it was considered that the experiences obtained in the project so far are worth disseminating if only to provide other implementers with food for thought.
In order to understand how Consensus evolved there follows a list of a few brief notes about the project.
4.1 Implementation Methodology
One of the primary principles in developing Consensus was to address one of the common issues with game engines and that is ease of use. Many games development houses have limited resources, and would appreciate a fairly transparent API, i.e. that the system appears as a local database and games engine.
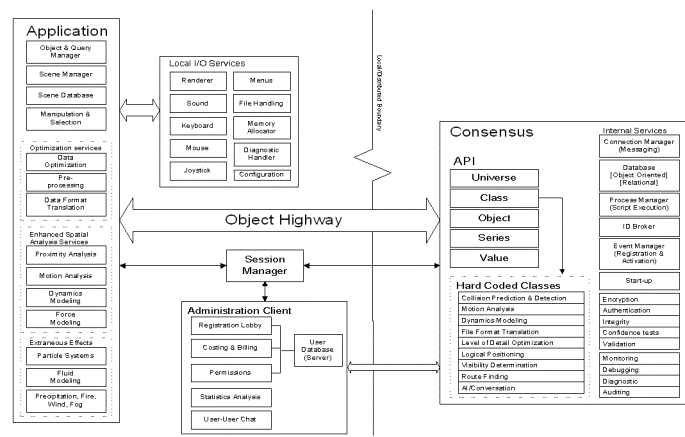
It is also important that we keep our own workload manageable so that development of Consensus doesn't grind to a halt under the weight of its own complexity. This means dividing the work into bite sized chunks or software modules (Figure 2):
· API for interface with the Scene Modeler application,
· Process Manager (for executing behaviors),
· Event Manager (for scheduling behaviors and state machines)
· Object Database (based on simple database),
· Simple Database (based on 3rd party engine),
· ID Broker for creating locally and globally unique ids for elements,
· Communications (publishing & subscribing to changes),
and 3rd party components wherever appropriate:
· Rendering: Microsoft Direct3D
· Scene Modeling: Motion Factory Motivate
· System Modularization: COM
· Operating platform: Microsoft Windows
· Back-end database: FairCom C-Tree
· Communications: UDP, MBone/Multicast
4.2

Technical Features
Like many game engines, Consensus was designed around an object oriented data model, and to support a Java-like scripting language (oriented toward expression of hierarchical finite state machines). The system supports this with a virtual machine and event processing system. Note that only objects are distributed, events are only raised and processed locally. There is also some support for controlling how method calls are forwarded, but this will be described later.
Because of integrity problems, complex data structures are discouraged. Indeed, the object is the most complex available. Strings of values or objects are also available, but while they may appear in the scripting language to have similar flexibility to strings or files, they are not intended to be used heavily (Interests, sets of objects meeting criteria, are often more suitable) - each time a new string is communicated, it must be realized as a global constant.
Implementation of the system has commenced in modular form using C++/COM, initially on the Microsoft Windows platform. While most objects are expected to be coded in the supplied scripting language, provision has been made for some objects to be hard-coded as well - these can be used on binary compatible systems (security sensitive). This makes the system extensible, e.g. to allow for ever improving collision detection and proximity monitoring services.
One intention of the design was to exploit the burgeoning market of sophisticated game engines, and the separation of scene modeling from world simulation allows us to do this. This may seem a waste of processing power to some, but with the rate at which performance is growing, the replication of some processing is soon outweighed by the benefits of this separation.
To help Consensus appear like a single-user game engine required transparency, i.e. transparent data distribution. And speed issues meant abandoning any transactions across the network. However shocking, it is refreshing and challenging to adopt best-effort principles throughout and focus only on fast ways to filter bad data from good - if it requires negotiation, the answer won't be worth the wait (however correct). If we embrace the fact that anomalies will happen, then we need only work towards making them evaporate as fast as possible.
To summarize the way Consensus distributes its worlds, there are two concurrent data distribution models:
· Hierarchical - child node publishes to parent
· Interest - peer node subscribes to peer
The data distribution process is continuously balanced by monitoring latency and coincidence of interest:
· Connections between least latency neighbors preferred
· Delegation to better source (object owners)
Arbitration over object state is achieved by assignment of ownership:
· One owner per object
· Ownership defaults to parent
· Ownership assigned according to interest and interaction rate
· Consequential load balancing
The widespread duplication of modeling provides comparable results to dead reckoning processes in other systems.
5 Concepts
Before embarking upon an explanation of how the system works, it's worth covering a few of the concepts involved.
5.1 The Participants
The platform supporting the Consensus system is comprised of players’ computers and any other computers simply providing extra resources (presumably remunerated). Each participating computer is termed a ‘node’ of the system. Nodes may communicate via all available means, whether via a network or broadcast medium.
5.2 Data to be Distributed
The units of data that are subject to distribution are:
· Value: Intrinsic/primitive value, e.g. 64 bit integer
· Series: A value string made up of two or more other Values
· Class: Definition of a group of values making up an Object, with single inheritance
· Object: Instance of a group of Values defined by a Class
· Interest: Instance of a group of criteria Values to match Objects of a Class
All, apart from Class and Object, are immutable - Interests are not mutable as otherwise there would need to be the ability to express interest in Interests. Objects, Interests and Series are passed by reference, and when these are communicated, the receiver will express a subsidiary interest in the associated data (it does not already have) and it will be communicated at a lower priority.
The class defines which members of an object are data and which are methods. The data members of a class are termed Properties. The method members of a Class are termed Operations (Series of instruction Values). A Class may inherit Properties and Operations from another class. Classes may be extended, and properties have some safe, unidirectional, attribute changes, e.g. protected to public, but not vice versa.
5.3 Relationships
There are two concurrent relationships between every node:
· A peer relationship – all nodes are considered fundamentally equal
· A hierarchical relationship – a dynamically changing responsibility structure
These correspond to the two modes by which the virtual world is distributed
· Subscribe or ‘pull’ - any peer may subscribe to any other peer
· Publish or ‘push’ - a child publishes its data to its parent
5.4 Arbitration and Ownership
Although Consensus is a distributed solution, that doesn't prevent it enjoying the advantages of a single server/multiple client solution, i.e. establishing a definitive version of the world on the server, that clients must defer to in the event of any disagreement over the world state. Consensus simply distributes this privilege among the nodes in the form of object ownership. This also makes the system more flexible in being able to balance ownership according to need and ability. Therefore every object has one, and only one, instance that represents the authoritative state of that object, i.e. all other versions are mimics. Given that the authoritative version resides in only one node at a time, the term ‘ownership’ is used to describe the relationship between containing node and authoritative object. The term ‘owned object’ is used to indicate the authoritative version, and 'unowned object' to indicate a mimic or computed replica object.
A similar system of ownership to WAVES [9] is used, albeit hierarchical in nature (in order to cope with node failure or partition).
It can be seen that the node owning an object is effectively responsible for providing the virtual environment in which the object is modeled. Because it is important that this environment concur with the consensus view of the world, ownership of objects is continuously optimized toward this end.
5.5 Causality
Given an ongoing time synchronization process between nodes, we are able to discard incoming object property values with less recent timestamps than other ones. The timestamp is the time the property was last updated by its owner. It is also useful in subscriptions to other nodes, i.e. an expression of interest includes a time criteria based on the oldest item of data held by the subscriber. The publisher then provides only the most recent data that meets the time criteria - there are opportunities for transparent optimization of this process.
In general, methods are always called on local objects, and when originating from an owned object are also forwarded to the current owners of the target object (unless the method is optionally marked as not requiring forwarding). The default is for all such messages to be processed regardless of timestamp. However, given that a message may be interrogated for its timestamp, it is possible for a method to determine special handling. In general though, and apart from the case when objects have the same owner, method calls will sometimes be duplicated, once when called locally from the non-owned object, and once when called remotely from the owner. It is therefore important to ensure that methods are designed to tolerate duplicate calls.
Being a processing overhead, important only to the fidelity of the simulation, events are raised and processed locally only. There is no point in communicating them, as they are entirely a product of the world model, and wherever the world model is reproduced so will the events be.
Again, all data is distributed, as are some methods, but events are not. This system is by no means perfect, and will patently give rise to many glitches. The thing to bear in mind is that if the objects are designed carefully, the glitches that do arise should be minimal and evaporate quickly.
5.6 Creation
Only singular entities should have the privilege to create objects, i.e. owned objects. Being singular, the scene modeler, and the node itself also have this privilege. Non-owned objects cannot create objects. This means that 99 mimic chickens will go through the same motions, but fail to create an egg, whereas the 1 real one will succeed. This egg will eventually replicate its way underneath all the mimics (sooner if anyone's looking).
This is achieved by having thread privileges relating to object ownership. Method calls issued from unowned objects do not have the privilege to create any other objects. They may still create events, but the events have no greater privilege.
The reason for this is the problem of duplicate object creation, for which there are two solutions: either objects can only be created by owned objects (the adopted solution), or object IDs have a direct relationship to their creator. The latter solution is a little tricky. It requires that multiple nodes must generate an ID, not only with the same class (easy) and instance number (tricky) of the required object, but also that this relate to the creator and the reason for creation.
5.7 Interest
The primary means by which a virtual world is modeled depends on interest expressed by owned objects in their environment. In this way a scene is composed of objects meeting the interest of a viewer (singular and equivalent to an owned object), i.e. in terms of what they can see and sense in their environment. These objects in turn will have expressed (somewhere along the line) an interest in objects meeting their interest, and so on.
The Interest takes the form of criteria which are to be applied to the properties or operations of desired objects. Interests are thus similar to conventional database queries, and like them operations may be performed on Interests as though they referred to collections of objects.
Interests are to be implemented as a special, immutable form of object, and like objects will only be created by owned objects. However, given that an object expressing an Interest will keep a record of that Interest, then unowned objects will still express the same interests.
Interests are reference counted and so when all objects have cancelled a particular Interest, or no objects are left (locally) that did so, that Interest may be discarded.
While Interests are 'expressed' they collectively determine the objects that are held in the local database (a cache of the virtual world). This also guides the selection of peers: towards those owning objects meeting the interest or having similar interests and good links with the owners; and parents: towards those having a superset of interests.
Interest also improves a node's ability to qualify for becoming an owner of the interesting objects. In some cases, interest is all that's needed to take possession of an object.
5.8 ID Brokerage and Lifetime
Globally unique identifiers are used heavily in Consensus, and for communication efficiency are allocated from a pool of fixed length numbers (rather than be long enough for collision-free, independent generation). ID reclamation from ‘no longer referenced’ items is performed as a background, distributed process.
IDs are only required at the point when a distributable item is first exported. Until that point, local IDs are used.
5.9 Object Lifetime
Objects may be freely created (by owned objects, or their processes) and may be frequently modified throughout their lifetime – the owned version overwriting all copies. But, this can't go on forever (however big the ID pool). Even if it did, some objects would be of such little interest that no node would have the space to store them. To forestall this slow decline it is likely that some objects will have some properties that clearly remove them from all nodes' interests, e.g. a bomb becoming an exploded bomb and marked as 'deleted'.
Suffice it to say that objects are never immediately destroyed, rather they are no longer of interest, nor express interest. They will eventually appear on a global 'hit-list' of ‘not recently used’ object IDs, which goes through a few stages, before the objects are then put on a destroyed list. Eventually, the final owners can reclaim the space used, and the objects IDs are re-used.

6 Distribution
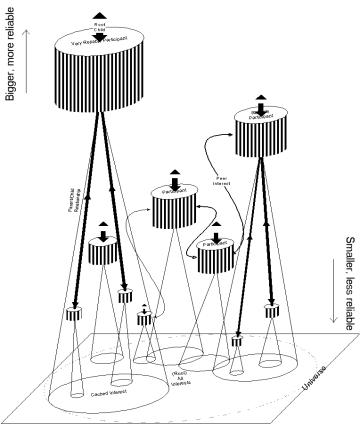
Unlike distributed processing systems or languages such as Obliq [5], which are not primarily oriented for data replication, Consensus is. This is because rather than processing, it is instead most concerned with distributed interactive simulation - for which data migration and duplicated processing are essential to performance and reducing communication. In other words, rather than make maximal use of available processing resources, Consensus makes maximal use of available communication resources. This entails continually optimizing the location of objects such that the results of their computations can be obtained by interested parties with as little latency as possible, and continually optimizing communication relationships between nodes with similar interests. All this also needs to be balanced according to the resources of each node. Consensus achieves this by managing two concurrent relationship systems (Figure 3): hierarchical (ownership responsibility and resources) and peer to peer (interest). The hierarchical relationship distributes the authority equivalent to that of the single server in a non-distributed system, and the peer relationship ensures that communication links are optimum.
6.1 The Hierarchical Relationship
In Consensus the hierarchical relationship is concerned with ensuring that each node has a more responsible and authoritative node with which to communicate for most of its needs, i.e. an effective server. This parent node is selected according to how good a match it is for most of the child node's current and short-term interests and that it has good communication links. The child node may of course, itself, be regarded as a good parent by another node.
6.1.1 The Responsibilities of a Parent
Parent nodes are ‘responsible’ for their children, and may entrust a child with ownership of an object it owns. A parent has an implicit interest in objects owned by its children.
A parent receiving a subscribing interest from a child will adopt it as one of its own interests, and will attempt to satisfy it from its cache. If the interest has a good match with the interests of any of its other children or other peer subscribers then they will be ‘referred’ to the child.
6.1.2 The Duties of a Child
Objects created by a child, and the changes made to objects it owns, are pushed to its parent. A child will also communicate its interests to its parent as an interest subscription.
6.2 The Peer to Peer Relationship
A node will communicate its own interests to all peers it is subscribing to, but not any children or currently subscribing peers. A node receiving a subscribing interest from a peer will attempt to satisfy it from its cache, and will implicitly refer its parent. If the interest has a good match with the interests of any of its children or other peer subscribers then they will be ‘referred’ to the new subscriber.
6.3 Choosing One’s Peers
A peer referral is judged upon how well the interest may be satisfied by the peer, which includes: interest coverage, connection (network proximity), subscriber load, node reliability, etc. A node receiving a referral may take advantage of it and decide to communicate its interest to the referred peer node. While this is typically to satisfy an interest it may be simply to explore the network, i.e. a two stage process, first to test the interest and second to subscribe. When the measure of a peer’s ability to satisfy an interest falls below a given point, the subscription to the peer may be discontinued. These heuristics for determining peers are carefully designed to avoid ‘thrashing’, e.g. continuous change with negligible overall benefit, especially when the subscription represents a significant load on the peer (cf. five people in the sea trying to use each other to stay afloat).
6.4 Allocation of Ownership
A node always knows what objects it owns and those its children and their descendants in turn own. Ultimately, there is a single root node. This does not necessitate that it contains the entire data set, only all ownership information. It is also likely to be highly reliable and available. It may not even contain any data, this task most probably being shared by its children.
Ownership of an object is determined competitively, and will be given to the node with most interest (excluding that via peers), frequency of access, and ability to satisfy interest subscriptions. However, ownership is only changed when a significant overall improvement is likely to be obtained across all would-be owners, e.g. in some cases ownership may be granted to a mutual parent, rather than any particular child, where several children are equally interested.
Ownership changes are achieved by the current owner relinquishing ownership to its parent, and that parent relinquishing to its parent, and so on, until a common ancestor is arrived at. The new owner then requests ownership via its own lineage from this ancestor. It is not expected that the root node will become a communications bottleneck, given that the mutual ancestor performing the ownership reallocation is unlikely to be the root node. The root will eventually receive updated ownership information, however.
6.5 The Determination of Parenthood
A node’s parent is determined in a similar way to object ownership, but is based on how well a prospective parent could satisfy the cumulative interest of the adopted child node - it is up to the child to seek the best parent. As one might expect, changing parent is not a trivial operation. Rather than ownership of a single object, ownership of all objects of the child and its grandchildren must be relocated via the new parent. Given this, a prospective parent must appeal significantly more than the current one.
It is assumed that if a change of parent is good for the child, it will be good for the grandchildren, i.e. the grandchildren aren’t left behind.
7 Processing
With the distribution system ensuring that each node is always tending toward the optimal set of objects and data for its purposes, once an object enters a node it can take advantage of the locally available processing resources. These include processing scripts (instruction sequences to a virtual machine) and registering interest in events. Some objects may be passive and only require processing in response to method calls, whereas others may be active, immediately requesting processing the second they enter a node.
7.1 Object Properties
Object properties are local or fundamental. The former indicates that they will not be distributed, but may still change. Fundamental, indicates that they will be overridden by updates from the owner of the object.
An object effectively has two values per fundamental property: Updated and Calculated. Methods always read the Calculated value. Incoming updates always overwrite both values. Unowned objects' methods will only write the Calculated value, whereas owned objects' methods will write to both. Given that only the Updated value is used to satisfy any subscriptions, the only data that is distributed is ultimately calculated by owned objects (the single server in distributed form). Local computation by unowned objects only serves to predict the world simulation.
It is possible to explicitly request the latest updated value of a property as opposed to its computed value, but this along with other details such as timestamps, are only available to the object's own methods.
7.2 Object Operations
Similar to conventional object methods, 'operations' are object properties containing instruction sequences. Information held in an object's class determines what are properties and what are operations.
At the lowest level, operations behave in a similar way to property read/writes. There is only one basic operation: Call, which is to supply a value and await a value returned from processing. This has two further variants: Read which omits a supplied value, and Write which discards any returned value. Operations can be considered as senders and receivers of messages (which are sometimes lost, duplicated, or disordered).
How calls of operations are processed by a node can be determined by whether the calling object and/or called object are owned by the node. This behavior can be specified by the applications programmer. Operations may sometimes be forwarded to the owned object (if not local), but are usually applied to the local object.
In simple terms, operations may be:
1. Local no forwarding
2. Forwarded calls from owned object also applied to owned object, discarding any return
3. Blocking calls from owned object also applied to owned object, waiting for return
4. Owner only calls from non-owned objects are ignored
These standard behaviors are developed from more precise call policy parameters for calls of operations from owned, and non-owned objects:
· Apply local, use local return
· Apply local and owned, use local return
· Apply local and owned, wait for owned return
· Apply owned, wait for owned return
· Ignore, use null return
Inbound calls are applied unconditionally, but may indicate whether return is required.
Only in a few cases will an applications programmer have to expend significant effort to ensure objects can tolerate lost calls, duplicate calls, and out of sequence calls. Default behavior should be satisfactory in most cases. Of course, it helps if the application programmer has an appreciation for an object's perspective, i.e. intermittent switches into subtly (and sometimes not so subtly) different parallel worlds with occasional overlaps. In view of this, it is possible for an operation to obtain details of the caller and the timestamp of the call, but it is not expected that this information will often be needed.
7.3 Events
Along with the ability to process objects' procedural behaviors in terms of operations, Consensus provides objects with the facility to register events for a wide variety of circumstances and to express interest in their outcome, i.e. an operation may express an interest in a particular ‘event’, specifying a particular operation to be called when the event occurs (if the object is still local).
Many standard events are available, e.g. to allow objects to be notified when they are created, they are replicated, their properties are updated, or their properties meet certain criteria. Nodal services are also available, e.g. to raise events when an operation between any two objects of an 'Interest of objects' meets certain criteria (distance less than x) – while not suggesting this is a good model for a collision detection service, it could be used in that way and there is plenty of flexibility to develop better systems.
Events are also useful when applied to the current satisfaction status of a particular object Interest, e.g. that an Interest has now localized at least one matching object.
Events are raised and processed locally only.
8 Fault Tolerance
Data is duplicated across so many nodes that information lost due to node failure is likely to be minimal. Information of most interest is duplicated most, and vice versa. Furthermore, enough information is stored by dint of the hierarchical responsibility relationship that relationships for nodes connected to a failed node can be quickly re-routed.
Reconnection of a node will favor its peers in any reconciliation, thus the consensus determines the state of the world. Nefarious disconnection thus disadvantages the node - on average.
With simple failure of a single connection, say between child and parent, it is a relatively painless process for the child to obtain a new parent and re-establish ownership. This is because ownership reverts up the hierarchy. The child node (along with its descendants) temporarily loses right to all ownership (though it may suspend the effect of this) and must obtain it again via a new parent. If its previous parent became isolated, then ownership will have reverted to a grandparent so will be readily available.
Rather than go into great detail about how fault tolerance is to be implemented – which would easily fill a separate paper – only brief summaries are given here, if only to delineate the minimum requirement for a system such as Consensus.
8.1 Failure Modes
The following modes of failure are fully catered for and have minimal impact on all sides:
· Node gracefully or abruptly disconnecting from network
· Node losing contact with parent, child, or peer
· Node with sudden deterioration in performance
· Node losing cache (major integrity failure)
· Root node gracefully or abruptly disconnecting from network
8.2 Recovery Modes
The following modes of recovery are fully catered for and have minimal impact on all sides:
· Node resuming connection with network after failure or graceful disconnection
· Node re-establishing contact with parent, child, or peer
· Node with sudden improvement in performance
· Node regaining cache (restoration from backup)
8.3 Node Creation and Termination
Administration of nodes is performed using conventional technology and covers the following:
· Creation/deletion of User ID
· Assignment of Node ID
· Initialization of local node (e.g. from CD-ROM, acting as a non-connected peer)
· Graceful first-time connection (location of suitable initial parent)
· Graceful termination (deletion of Node ID)
8.4 Catastrophic Failure
In the event of major failure such as network partition (US loses contact with UK), the nodes in each partition will gravitate into two hierarchies. No special action is required. Even in the unlikely case of nodes in one partition having prior contact solely with the other partition; nodes will know to contact well-known nodes in the same partition or listen on a multicast or broadcast channel. Reconnection will resume at the most senior levels, as though it was only a higher level branch of the hierarchy that originally became disconnected.
In general, any isolation or partition of any set of nodes will eventually result in the isolated nodes connecting together and operating as though they were the entire system. However, as there is a single root, the root side partition will continue as normal, assuming ownership of the other partition, the isolated nodes. The isolated nodes can only ever operate in the interim assuming ownership of objects as at the time of partition, i.e. they can't elect to own further objects. This is because it is only worth continuing with the expectation of imminent reconnection - there is nothing to be gained by becoming independent except divergence.
Record of the state of ownership at the time of isolation is kept such that upon reunion, arbitration over state is relatively fair. However, as one might imagine, reconciling any amount of divergence will not be painless. An application can of course avoid this by suspending significant activities throughout this isolation (make the scene go foggy, say).
9 OTHER ISSUES
9.1 Comparison with Tuple Space
In a similar fashion to Linda and the Tuple Space paradigm [7], we have the ability to store in the distributed database: Values (arbitrarily sized data elements) and Objects (groups of Values, comparable to ‘tuples’). We can also express interest in objects that meet particular criteria (Interests, comparable to ‘anti-tuples’). The idea is, that an ‘Interest’ is expressed by the player (say, of all objects in the scene), and the database will contrive that objects meeting this interest will be prioritized for being held locally (or cached), be updated most frequently, and be modeled most accurately. Unlike Linda, the object (or tuple) is mutable and not generally removed (except as a garbage collection operation), therefore there is little need for the Linda in(at) operation.
The similarity with Linda operations can be summarized as follows:
Elements: Values or Series
Tuples: Objects composed of groups of Values (defined by Classes)
Anti-tuples: Interests, similar to Objects and similarly defined by classes, but members are used as criteria. Compare with Objective Linda [10].
out(t): Object instantiation – common operation
in(t): Object deletion – rare, garbage collection operation
rd(at): ‘Expression of Interest’; determines Objects cached; can be treated as collection
NB Unlike Tuples, Objects are mutable, though Values, Series and Interests are immutable.
9.2 No Zoning
Rather than have a system of geographically zoning the virtual world and expressing interests in terms of neighboring zones, the Interest system is used. This is because Interests are a more general and flexible means of specifying information required to model a scene. Moreover, they do not preclude the potential for transparent pre-processing optimizations such as zoning, indexing, etc.
9.3 Multi-Format Resource Data
Given that one of the primary objectives of Consensus is to allow multiple levels of object description and detail, the ability to have multiple representations of the same information is transparently achieved by Consensus. The Interest system allows that only the formats of interest (compatible with the scene modeler) will be cached locally. It is also fairly straightforward to design classes that auto-translate formats given a single format of a new item.
9.4 Administration
Given its high security requirement, administration of Consensus applications is probably best achieved using conventional technology, and will cover the following areas:
· Privileges
· Monitoring & Auditing
· Security
· Registration & Licensing
· Charging & Remuneration
· Accounting
Various capabilities concerning development of Consensus applications, such as the ability to modify classes, would be allocated as node privileges, i.e. ownership of class objects is only granted to the privileged.
There will be a few background processes operating on each node (almost a distributed process). Some of these will be diagnostic, whereas others will monitor database integrity and sample operations. In this way tampering with the database, either manually or via a virus, can be detected without much performance penalty. Application level, malicious or accidental development of problematic objects, can be dealt with case by case, e.g. endlessly replicating objects, could be dealt with by arranging to decrease the interest of objects according to their number, i.e. the 100th grain of sand is of less interest than the 10th.
It may be more enlightened to consider operating pricing on an egalitarian basis, where every node was both a potential service provider as well as consumer. This would mean that nodes were charged based on their subscriptions and the messages they send, but remunerated based on the subscriptions they service and messages they process. A subscription would be priced according to its quality, which depends on its publisher, i.e. capacity, performance, bandwidth, latency, availability, reliability, etc. Measurement of such quantities would be performed similar to security monitoring, by background processes and sampling - this would also use similar techniques to detect anomalous pricing. This pricing scheme would allow that nodes acting as servers would obtain income, whereas occasional players would see a net outgoing.
10 Conclusion
Consensus is a pioneering system further demonstrating the case for adopting a distributed approach, and additionally proposing the sacrificing of integrity, to obtain minimal latency, greater flexibility, and scalability.
10.1 Suitability
Consensus is ideal for massive multiplayer games and all other large scale interactive entertainment where simulation fidelity is not paramount. There is some potential for its use as a basis for computer supported collaborative working applications, e.g. architectural design.
Safety and accuracy critical modeling applications are not suitable, e.g. collaborative control of telerobotic devices for remote surgery or underwater engineering, and battlefield or aircraft simulation.
10.2 Novelty
Consensus is novel in taking a holistic and highly generalized approach in the design of a system to support indefinitely scalable interactive entertainment. Furthermore, it is designed to allow live and evolutionary upgrade of both the system and the applications it supports.
No single element of the design is novel in itself, but together they represent a novel combination. The system does not attempt to hide the unreliability and poor quality of the network, but like the human brain, exploits massive redundancy to suppress anomalies.
10.3 Improvements & Future Directions
Only once Consensus has been tested in earnest, can we begin to explore how changing message reliability might affect the quality of the simulation process, especially if there is a side effect in latency terms.
It may be worth exploring whether inter-object communication could be improved if it were entirely unidirectional, i.e. no object could affect another by sending it a message. This would mean, for example, that a balloon object would have to notice the pin touching it before it would explode, i.e. the pin doesn’t tell the balloon to explode. Such unidirectional messaging is currently supported but not obligatory.
Consensus has the potential to support distributed processing applications, but as it is not primarily designed for such, it is unlikely to be worth exploring this alternative usage.
10.4 Importance
Consensus is important in being one of the few scalable, distributed systems designed from the ground up for application to the large scale interactive entertainment industry, as opposed to military simulation. Its relative simplicity, transparent nature, and inherent scalability make it a particularly attractive solution for adoption by companies with relatively small R&D budgets.
Its scalability makes Consensus a viable technology now and in the long term.
Acknowledgments
I would like to thank Pepper's Ghost Productions for their vision in funding this paper and the trial implementation of some of the ideas it describes. Thanks also for the encouragement of Don Brutzman, Simon Everett, Jez San, and Chris Mills. Some prior work has been funded by Gary McHale.
References
[5] L. Cardelli. A Language with Distributed Scope. Computing Systems, 8(1):27-59, January 1995.
[1] Total Entertainment Network™ (www.ten.net)
[2] MPath Interactive, Inc. (www.mpath.com)
[3] British Telecom - Wireplay (www.wireplay.com)