Strategies for Scaling Interactive Entertainment
Crosbie Fitch
Pepper’s Ghost Productions
Introduction
If the last century was all about the moving picture and its attraction as an enhanced storytelling medium able to scale audiences from a privileged few to the majority of the people on this planet, then the next century should see us similarly scaling up the audiences enjoying interactive computer graphics as an enhanced storyliving[1] medium.
To attain the capacity for large, collaborative audiences, especially as large as those enjoyed by film or television, will require technology that can scale to audiences of millions or even billions of simultaneous participants. The current state of the art which aspires to typical audience capacities of tens, hundreds, or even thousands, reveals more about the limitations of current systems' designs than it does about their potential.
Instead of being broadcast like television - simply sending the same images to everyone - collaborative entertainment requires mass distribution. Instead of consuming identical images from the same point of view, participants will not only require a unique, personal perspective, but will also be producers of effects upon their immediate environment.
This is a distribution problem comparable to the logistical nightmare of distributing perishable goods between fussy, small volume producer/consumers. In our case, the highway is the Internet, and the goods are packets of information with expiry dates measured in seconds, which are produced and consumed by individual users whose tastes continually change. Unfortunately, suffering a similar problem to city road networks, the Internet can only offer delay prone or unreliable journeys. It is thus very difficult for people spread across the network, say a New Yorker, Parisian, Falklander, and Muscovite, to collaborate with each other and still pretend they're in the same place.
Strangely familiar, we are already seeing attempts to solve the distribution problem by expanding the capacity of the network - akin to widening the roads. Whilst this is laudable, the strategies I present in the following chapters are about making the most of whatever networks we do have, i.e. ensuring vehicles are full to capacity, that the most essential goods and journeys are prioritized, and that depots and warehouses are used to minimize trip distance.
Overview
At its simplest, our supposed objective is to model an indefinitely sized virtual world and make this model available for interaction to each of an indefinite number of networked computers.
Understanding the difficulty of the solution, given the shortcomings of conventional approaches, should lead us to develop some strategies to make our task more tractable - we need to take a few steps back and appraise the edifice confronting us. This is perhaps a luxury few have been able to afford, with teams developing technology in this field typically being pressured to obtain viable short-term solutions rather than develop according to a long-term strategy.
The problem is essentially one of scale - massive scale - and the industry generally has a poor record in dealing with such problems, at least when addressed directly. It really is no good scaling up solutions designed for small scale problems. We have to ensure that the solution has scalability designed in it from the start. On an economic basis this will entail a solution operating at the unit scale, i.e. being as viable on one or two low powered computers, as on large numbers of powerful computers. We should expect that our final solution will be small and simple, albeit challenging to design.
The Need for Scale
The best demonstration of the attraction of large scale virtual worlds, is that of real life: billions of simultaneous players in a colossal universe - with very few deciding to quit early. Of course, many would like to escape to another life, if only temporarily, and cinema, as a refinement of such an escape, attracts large audiences the world over for its ability to provide an experience of a virtual world - albeit passively.
If we can provide even a crude semblance of another world, in which players can explore an alternate reality interactively, it has the potential to become our world’s most popular leisure activity.
The best virtual worlds will be those that offer players the most freedom - typically meaning freedom to explore, create and interact. Hand in hand with this freedom goes the absence of apparent limits. This entails a system that can scale along with the growth of a virtual world and the number of people playing within it. Inevitably, this scalability means the system has to cope with large scale - large enough to satisfy its users that it is unlimited. So by ‘large scale’ we’re talking about figures at least the same order of magnitude as the growing number of users with Internet connections.
Challenges of Scale
A large scale virtual world, in some ways like the Web, is too big to launch in one go. Not only the content, but also the mechanisms that embody the laws governing the virtual universe are also likely to need to support live revision. Even the software system that supports this is likely to be developed piecemeal.
· It’ll be too big to launch in one go, too big to recall, too big to develop wholesale.
·
The entire system must support live
content development, live update, and uncoordinated system upgrade.
One of the problems of truly scalable systems, is that they can no longer be treated in the same way as systems based on a single workstation or site. It is no longer feasible to stop the system, or undo any changes to it. Even fairly simple systems such as the Web present technical challenges when it comes to improving the underlying technology (IPv6, XML, etc.). Unlike workstation applications, or even operating systems, it is not so easy to make a wholesale change to a distributed system (such as the Web).
|
Client/Server is not a solution In order to have a scalable virtual world modeling system we have to discard naïve notions of having one or more servers supporting a growing user base. All this does is end up reflecting the network of users, i.e. for each user on one side of an access point, you need a corresponding computing resource on the other side. This may work when you are certain that the ratios will be low and remain so as numbers scale, and will remain cost effective, e.g. electronic mail is a low ratio task (in price and performance) and Internet service providers can expect their server resource to remain in proportion with the income from their users, and thus remain economic. When you need computing power comparable to that of the user's computer, and it doesn't look like the ratio will lessen for the foreseeable future, then it is short-sighted to adopt the client/server approach. The better alternative is to effectively locate the server on the user's computer. That way you avoid communications bottlenecks and are almost guaranteed that for every additional user there will be additional computing resources - all that has to be provided is the software. The only remaining problem is to ensure that the workload is appropriately distributed across all these localized 'servers'. |
A virtual world will reach a vast size, serve a huge population, and persist indefinitely – it can match the Web in these terms. So, players, content, interaction, and persistence, will all make increasing demands upon the system. Supporting these precludes any bottleneck in the system or unambitious limits to capacity. Whatever system is arrived at, it has to be designed from the outset without any limits based on assumptions of the initial number of users, e.g. a client/server approach built around an ability for multiple servers each to support 500 users, may scale up to 5,000 or even 100,000 users, but collapse thereafter because inter-server communication did not scale.
Most companies in this industry (a lot of them games companies) do not have budgets as big as the US department of defense. A system to support a variety of indefinitely large virtual worlds for exploration by an unlimited population of simultaneous players cannot be designed without consideration being given to the amount of programming effort required. It is also unlikely for there to be sufficient resources to co-ordinate effort between companies - even if they would be willing to share in a comparable venture. Therefore we have to implement such a system using a simple, open and modular approach. This favors having functionally identical software on every participating computer, that scales according to the local resources, and automatically makes contact with other participants.
The Problem
Firstly, it would be sensible to ensure that we establish the problem before considering strategies to solve it. Let us begin with a reasonable set of requirements for modeling a virtual world:
1. The world consists of a set of objects that allow definitions of such things as position, appearance, behavior, etc.
2. There is a database: a container of the virtual universe or world, which has capacity for an indefinite number of objects
3. Objects have properties: an arbitrary amount of information that can be associated with each object
4. Objects have methods: properties that can be defined as the result of computations - that may be based upon, and may modify, other properties of the object
5. Objects can be defined within a hierarchical classification scheme, and methods can be selectively inherited
6. Methods can express an interest in other objects whose properties meet particular criteria and perform operations upon them as a set
7. Methods can be based upon methods of interesting objects
8. Each of an indefinite number of computers can connect to the virtual world and interact with interesting objects (via their methods), in order that the objects may be presented to a user for their interactive entertainment
9.
The virtual world is presented
consistently to all concurrently connected computers
Most existing approaches have opted to arbitrarily limit one or more of the above requirements in their design. Some will locate the database entirely on a single computer. Some have it such that methods are implicitly interested in all objects within their locale, and define the locale separately (on a grid basis, say). Some have a fixed or inflexible classification scheme. Some limit the number of computers that can connect at any one time.
The challenge of arriving at a scalable solution is to arrive at a design which limits each requirement only in terms of the total resources available, i.e. storage, processing, and bandwidth. The best scalable solution will make maximum effective use of total resources, and at all times.
Meeting the Challenges of Scale
Initial Strategies
One thing
we should have learnt about computer systems by now is the fact that the
technology they are based on is likely to continue its inexorable climb up
exponential performance curves. In other words, workstation processing power
and storage capacity look set to follow Moore’s law well into the future. We
may even take a gamble that communications bandwidth capacity, at each point
from user to user across the Internet, may obey a similar law. However, if we
also take Parkinson’s law into consideration, it suggests we should expect that
work will expand to utilize all these resources to the full. Thus, Internet
traffic is very likely to increase as quickly as capacity becomes available.
Given this, any system that attempts to enable massively multiplayer games must
be designed to take advantage of ever improving local resources. Moreover, it
must also take the precaution that network latency will not steadily improve
like everything else - based on the assumption that latency is related to
network traffic as a proportion of network capacity. Latency is a problem
today, and it should be addressed by a scalable system, in spite of any hopes
that the problem will go away.
The
conventional approach may be to limit the application in terms of size and
flexibility, target a particular platform and optimize specifically for a
limited set of supported cases, e.g. 32 players across a LAN, 16 across the
Internet, or on a grander scale, 10,000 players supported via dedicated servers
and high bandwidth backbones. However, until a system can cope with numbers as
large as user populations as well as ‘small’ numbers, then we’re not really
talking ‘scalable’.
One example
of a virtual world that is scalable in some sense is the World Wide Web. Any
number of computers can participate in providing the HTML world, and any number
of users can explore it at any time. Unfortunately, by the Web's very nature,
interaction is fairly limited.
In considering
the problem of designing a system that will scale up to support the virtual
worlds people will expect in the next millennium, we should dispense with all
artificial limits. This means no artificial limit to the size or flexibility of
the model, nor any limit to the number of participants or the extent to which
they may interact with each other or the virtual world. Of course, there are
still physical limits, and we can only hope to ameliorate or hide these.
This brings
us to two main strategies: designing the system to make the best use of the
resources available, and designing the user’s interface to the virtual world
such that the user does not expect more interaction than is actually available.
Scalable Quantities
Observing that 'scalable quantities' includes small numbers in single figures as well as very large numbers, any scalable solution must still perform well with small numbers. Though, understandably, it cannot be expected to be as effective as a system optimized for small numbers.
The following quantities must be scalable:
The Resources
· Number of computers
· Storage per computer
· Processing per computer
· Communications bandwidth between computers
· Reliability of computers and messaging
The Model
· Number of object classes
· Number of objects
· Number of properties per object
· Number of data elements
· Number of interests
The Demand
·
Number of users
We can now make some useful observations upon the consequences of increasing resources to the system:
1. Overall simulation fidelity will increase as the resource per computer ratio increases, particularly if computers without users are added.
2. Scene modeling fidelity will increase as the resource per computer ratio increases.
3. Imaging quality will increase as the processing per computer ratio increases.
4. The capacity of the virtual world will increase as the total storage increases.
Current Scalability
Individual computer systems are fairly scalable as it is. If your spec is a decent operating system, a C/C++ compiler, and Open GL, then in terms of being able to scale the power of the system, it's just a question of time and money (how long you wait for technology to improve and how much you spend in the interim). However, the instant you start trying to scale user capacity, by spreading the system across an indefinite number of linked computers it can easily turn into a logistical nightmare.
To make the system as simple as possible, it is worth looking a little more closely at what tasks and resources need to be shared across all computers, and what can be scaled in situ.
Extending the Pipeline
Each user will only need to experience a small portion of the virtual world, typically only the scenery that they could sense, or that may have an affect upon their sensors (camera, microphone, etc.), directly or indirectly. This is equivalent to the user's immediate interest, and the term 'scene' is used to indicate this portion.
It is important to see the distinction between information necessary to model, depict and realize the scene, and information necessary to simulate the virtual world encompassing the scene. The former is concerned mainly with visual quality and realism of appearance, whereas the latter is concerned mainly with physical interrelationships. For example, you do not need to know the current configuration of a birds wings to control where it is flying, but this may make it more realistic to the user. Similarly, you can generate a random number between 1 and 6 for a die falling, but if this is to be shown to the user, then it can't look like it's fixed, even though in some ways it is [1].
The reason for this distinction is to take advantage of the fact that to make the presentation of a virtual world consistent only requires that its salient details are consistent, i.e. its essential simulation, as opposed to the modeling of its scenery. This is discussed further in the next section.
So, as we can now see that the virtual world only needs to be consistent in terms of simulation, we are able to define the division between the local system and the distributed system:
· Each computer is wholly responsible for the visual and ephemeral quality of the scene, and is thus dependent upon local resources.
·
The distributed system is responsible
for the fidelity of the simulation, and is thus dependent upon distributed
resources.
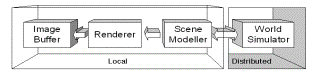
![]()
Just as the task of rendering has been extracted into a separate stage of a pipeline, thus allowing it to be scalable in hardware, so we can also extract the task of scene modeling (Figure 1), thus allowing the end-user to determine how sophisticated they want their scenes to be (where this sophistication is independent of the essential behavior of the simulation). This then allows us to focus on the minimal amount of information that needs to be consistent across all computers.
Accepting the Equivalence of Experience
A philosophical assumption people tend to make, is that once they agree that other people exist (as individuals), they assume that everyone else experiences the world in much the same way as themselves. It's perhaps that because we appear to each other as similar beings, so we conclude that our perceptions must work in the same way. Helping reinforce this notion, we describe our perceptions using the same agreed set of names, but we only assume that we all experience, say, a 'red apple' in the same way. It is conceivable that the color 'red' may be experienced by someone else in the same way that I experience the flavor 'acidic, sweet', and someone else may experience it as the note 'C sharp'. As long as we have grown up with these associations they would work just fine, though if we have a reduced set of experiences it could sometimes be problematic, for example, color-blind people might not find out that they're deficient until they try their hand at an interior decoration business.
If you thought the foregoing was quite irrelevant, you've got my point precisely. Because only we know what we experience, it is just as irrelevant that when we travel in a virtual world we should experience it in the same way as each other. As long as we can verbally describe the scene that appears in our VR headsets in the same way as everyone else, then that will be enough to convince us that we participated together.
Taking this to extremes, it is possible that one virtual explorer may have a text interface (just like a MUD[2]) by which scenes are textually described and actions executed by typed command, whereas another may have a real-time stereo 3D ray-traced scene with psycho-acoustically accurate stereo sound and a full body-suit. Only the programmers need know how different the two experiences are.

![]()
The conclusion is that you can have networked computers sharing the task of modeling a virtual world, and still allow independent scalability of each computer's modeling of the scene. Whether one user sees a photorealistic 3D rendition of a ship at sea, and another user sees a 2D caricature of the same thing, doesn't matter because both users end up with an equivalent interpretation of the virtual world and so can corroborate their perception without confusion (Figure 2). The quality of the experience is thus independent and it's up to the user to control this, inevitably according to how much they can afford.
Modeling the Scene
The task of scene modeling is a familiar one, and with it occurring locally and in a distinct stage of the production pipeline, existing systems will slot in quite nicely. The only remaining issue is how the scene modeler obtains its information from the world simulator. This simply requires that the scene modeler is aware of how to create a camera in the virtual world and then interrogate it for details of the scenery meeting its interest. Whoever created the scenery will have associated with it information meaningful to scene modelers, and will have specified how the information may be requested. Therefore the scene modeler will need special details of the virtual world. However, there is no limit to how many different conventions there may be for scenery description, and similarly no limit to how many scene modelers may be implemented.
At the risk of laboring the point, how well a particular scene is modeled and rendered is dependent upon the locally available processing power. Just as one system may render a 3D view flat shaded with hidden surface removal, and another may render the same view fully ray-traced, so scene modelers may vary in how they interpret the primitively modeled global behavior into a more realistic and richer local representation, e.g. an autumnal walk through a forest may be a crude, hand animated walk and just half a dozen leaves wafting about, or it may involve perfect perambulation and millions of individual branches swaying and leaves fluttering.
The scene modeler also takes responsibility for conveying the user's interactions to the virtual world simulator, e.g. joystick control of the camera position, or suggestions to an avatar as to the direction in which they should walk. How the user is manifested within the virtual world, indeed their whole relationship with it, is a topic worthy for separate discussion. However, it is worth pointing out now that this can vary from a third person, god-like observer, to a first person participant. Of course, our inescapable friend latency tends to determine where in this spectrum the user's relationship comes (and there's no reason why it shouldn't change during a session if relative latency should change).
So, a representation of the virtual world is stored in the distributed container or database, a portion of which is of course held locally. This portion has to be sufficient to pass interesting scenery to the local scene modeler, which may then pass a 3D representation of the scene to the rendering system. To avoid the risk of appearing too focused on visuals I should add that, of course, the scene modeler may also pass other details, e.g. interesting noises to a sound system.
Leaving the ongoing problem of improving the quality of the interactive experience, visual and otherwise, to the specialists, I will now focus on the problem of ensuring that those interacting with a virtual world don't notice any discrepancies between their experiences, either during a session or when they discuss them with each other afterwards.
Simulating the Virtual World
While there may be a variety of schemes for describing objects in the virtual world, it is important that the virtual world is simulated consistently by all computers. Therefore there must be a common scheme for describing the essential behavior of objects.
Each computer needs to have a 'game engine' or 'virtual machine' that can run a common instruction set, just like a Java virtual machine. This will need to support typical simulation requirements, e.g. a Java-like scripting language, but sophisticated enough to compose hierarchical finite state machines, say. This also entails support for programmatic raising of events and subsequent concurrent processing, thus multi-threading behavior is required.
It would also be useful to support just-in-time compilation, and perhaps also provide support for precompiled classes - though these would need to be authenticated.
We also need to be able to express interest in objects, and criteria defining that interest. Thus we begin to venture into real distributed systems territory.
The feature list of such a distributed simulation platform that would meet our needs can be summarized as follows:
· Java-like scripting language, i.e. high level, object oriented language.
· Events: synchronization objects, flags/semaphores, queued & ordered events, etc.
· Multi-threaded execution
· HFSM capabilities
· Support for hard-coded objects (authenticated)
·
Interests, i.e. Linda-like entities [3]
So, the database (distributed across all computers) that contains all the objects in the virtual world, must also be able to process them, in order that they may simulate complex behavior.
Now we need to decide how to share the workload of processing all the objects.
Latency is the Key
Two 'laws' have a key part in determining that latency will be the most significant factor in a system's design if it is to scale over time:
· Moore’s: A law appearing to govern storage capacity, processor power, and communication bandwidth, in relation to time.
· Parkinson’s: A law appearing to govern users & traffic, and application size & complexity, in relation to capacity.
For want of a similar law governing latency, I suggest that network latency obeys the same law as average journey time in London, or other similar city, i.e. it doesn’t matter how technology progresses, journey times arise out of what people will tolerate for a given cost (where potential traffic exceeds capacity). Taking this analogy further, I'd make the following somewhat frivolous comparisons between transport of data and people:
|
Internet Connection |
Urban Transport Equivalent |
|
Modem |
Walking/Running |
|
Prioritized Packets |
Bicycle/Motorcycle |
|
Private Network |
Helicopter |
|
ISDN |
Car |
|
T1/T3 |
Lorry |
|
MBone/Multicast |
Bus/Train |
When you take into consideration the fact that journey times across the capital have increased since the days of horse driven hackney carriages [2], the plausibility of similar behavior with network communications does not bode well for any hope in reducing latency.
Even if the Internet generally becomes more sophisticated, incorporating packet prioritization, guaranteed level of service, dedicated backbones, etc., unless traffic is priced off the network, latency is likely to remain a problem.
My proposition is that designing a system around Moore's law is not a gamble, but a sound investment, i.e. any storage or performance cost incurred by minimizing the effects of latency will be negligible - and if not now, sooner rather than later.
Therefore, the key design strategy is to prioritize the amelioration of latency. Furthermore, given that latency's significance is proportional to the amount of communication that takes place, this strategy is equivalent to a strategy where communication is treated as an exorbitantly expensive resource and consequently most effective use is made of it as possible.
Annealing the System Design
One design technique that I'd like to present now is to explore in a thought experiment how the system design would change if resources were successively more restricted. Given our strategy to make communication the most expensive resource, this is restricted first. Remember that the system is composed of an unlimited number of users all of whom need to interact with each other and a continually changing virtual world.
Step 1: Unlimited Resources
In this case it wouldn't matter how the system was designed. The entire database could reside on a single computer and all others communicate with it, or the database could be spread evenly, even arbitrarily. It's not critical, because resources are unrestricted and therefore infinite, i.e. communication is considered instantaneous. Systems designed using this principle are only likely to be viable for a few users connected via a LAN.
Step2: Unlimited Bandwidth, but with Latency
Given the likelihood of frequent communication in both directions between computers, a star topology may be considered to be as good as any. However, in the presence of latency this may tend to double message journey time if routed via a hub. An alternative would be to have all computers contain the entire database and broadcast changes to every other computer.
Systems designed on this principle and with a star topology are probably destined for a broadcast based network, e.g. TV or satellite broadcast of world update, with each participant uploading via the Internet only their own interactive changes. However, though the bandwidth in this case is large, it is not actually unlimited.
Step 3: Latency and Limited Bandwidth
In this case we can no longer afford the star topology because bottlenecks are inevitable. We now have every computer contain the entire database and have to be careful in ensuring that changes are prioritized according to their importance and who needs them most. With limited bandwidth we must also take pains to keep message size to a minimum, and this means making the communication as high level as possible.
Systems designed on this principle are likely to be expensive although effective.
Step 4: Storage is limited
When storage becomes limited, very large virtual worlds are unrealistic and one can no longer expect every computer to contain the entire database. This is particularly wasteful when one considers that the user (or users) of each computer is likely to be interacting with a small portion of the world at any one time. The solution is then to prioritize what is stored in the local database, e.g. in the following order: what can be perceived, what may be perceived at a moment's notice (in the immediate vicinity), what may be perceived shortly, etc. The less immediate something is, then the less important the information is, and the less fidelity is required for it. This extends the idea of 'level of detail': the lower importance something has, the less information is required about it. Thus a mountain range may only need a colored 2D profile to be used as a scenery backdrop, i.e. without 3D details and without additional information regarding every tree and ravine that may be on it.
Step 5: Processing is limited
The restriction of processing power is
coincidentally benefited by the previous restriction of storage. The fact that
there is now much less information about the virtual world stored locally also
means there's less processing to do in performing its simulation. However, with
processing resources at a premium we need to conduct simulation such that the
most immediately relevant and salient behavior is prioritized. Thus the
behavior of a wolf in bushes nearby may be more important than that of a rabbit
in a warren underfoot.
We thus end up with a distributed solution, but only viable across the Internet if we assume that communication will always represent the greatest resource cost. Moreover, while this can guide our overall design strategy it is still important to consider the other operating conditions that may impact the design to a greater or lesser extent.
Operating Conditions
Up until now the conditions under which the system is to operate have only been discussed in fairly general terms. However, if we focus a little more closely at The Internet, the most likely target platform, then the list grows into the following:
· Indefinite numbers of computers to participate
· Continually and unpredictably varying connection latency and bandwidth
· Occasional and unforeseeable sustained disconnection and computer failure
· Available system resources changing during and between sessions
· System software to be upgradeable between sessions
· Virtual world model to be revised live during sessions
· Expectation of growth in number of participants, and exponential increase in performance and storage per computer
· Expectation of growth in bandwidth, but little improvement in latency
·
Risk of malicious data corruption
To be fair, we should also accept some fundamental limitations of the system, e.g. the system cannot be telepathic and so in some circumstances latency will be apparent. We can add the following inherent limitations:
· Scenery delay (hidden or otherwise) proportional to the rate of change in location in the virtual world
· Overall quality and simulation fidelity to be proportional to connection quality, local storage and processing resources
·
Virtual world size to be proportional
to number of participating computers
From all this we can begin to address the design issues involved in arriving at a system that can operate effectively subject to these conditions.
Strategic SYSTEM Design
Now that we have seen the problems involved in obtaining large scale interactive entertainment and the type of strategy that is required in solving them, we can begin applying that strategy to the design of a scalable software system.
Distribution based on Interest
Distributed across countless computers we have a database of all the objects in the virtual world, and a means of processing the simulation behavior for each of them. Each computer is concerned with presenting a portion of the virtual world to its user, allowing the user to interact with it, and ensuring that any ramifications of this interaction not only occur locally, but are also communicated to every other computer that may be interested (at that point or thereafter).
In addition to that, each computer needs a means of specifying the various parts of the portion of the virtual world that it's interested in, and how interested it is in each. Of course, this interest has to be specified to one or more other computers, so there also needs to be a means of determining to which computers such interests should be expressed. Conveniently, this is provided as a consequence of the solution to the following problem.
Consider that a lot of the objects in the virtual world will be stored and simulated by more than one computer. There also needs to be a way of reconciling the likely variations that will exist between all the different versions of particular objects. As discussed in the next section, this comes down to a matter of simple arbitration.
A Hierarchy of Responsibility
Whenever you have more than one computer interacting with a database, the problem of deciding how to arbitrate between conflicting transactions inevitably raises its head. Given latency is our guiding light, we have to immediately cast out any classic transactional system, whether it be simple record locking or anything else. This is because we simply cannot afford any communications overhead - either a change to an object is accepted or it is discarded, no further communication is warranted.
Therefore, the distributed database needs a mechanism for arbitrating between differing object states (in the process of reconciling notionally identical objects simulated by each computer). This will simply be a decision as to which of two states an object should take: between the resident one, or an incoming one.
I have deliberately avoided discussing this subject until now, as I believe it is allowed to bias the design of other systems much more than is necessary. One of the reasons I suspect that a client/server or star topology is used, in spite of the consequent communications bottleneck, is that the system is patently assured of consistency. This would be by dint of the single server providing obvious and absolute arbitration over any conflict of object state between two or more clients. However, just because object state is arbitrated does not necessarily require that the arbitration must take place on a single computer. It can be distributed just like everything else. Indeed, responsibility for an object's arbitration, like the object itself, can also be allocated according to interest, particularly as the computers most interested in an object would tend to be most interested in its correct behavior. However, only one computer can own an object, so this can be determined competitively according to a heuristic based upon a computer's interest in the object, how well it can simulate the object, and its ability to communicate the object's details to others.
To distribute arbitration means distributing responsibility or ownership of objects away from a central server, but with the proviso that it is always known which of the several duplicates of an object is the authoritative, owned one (the erstwhile centrally held one). Furthermore, in light of the high probability of abrupt disconnection of computers, we need to keep track of who owns what objects, so that in the event of disconnection there is a well understood, implicit succession of this ownership, and that upon reconnection the original owner is reconciled appropriately.
I'd suggest that a hierarchical relationship between all computers is established to clarify this responsibility, and provide an obvious path of succession. The burden of responsibility will require keeping track of owned objects and those owned by ones subordinate computers. This means requiring those same subordinates to ensure they keep one informed as to the latest states of those objects. Therefore, it begins to appear that those computers higher up in the hierarchy will necessarily be the more reliable and those with superior resources. Ultimately, there will be a single computer at the root of this hierarchy, however, it will not necessarily need to contain all the objects it could potentially own (the entire virtual world), simply ownership details of all objects. All we would need to do in this case is to ensure that the computers at the second level of the hierarchy are fairly resilient.
Sharing Information
Each computer will store as much of interest as it can. This interest is likely to extend to areas of the virtual world that are likely to be visited next, which typically includes places previously visited. As one might expect, computers with large storage resources, are likely to contain a large portion of the virtual world. If as is bound to happen, there is another computer interested in part or all of that information, sometimes it may be more effective for the two computers to exchange news between each other directly rather than via another computer.
There are two types of such a co-incident interest that are worth discriminating between. One is a peer interest where two computers' interests intersect where they both have an active interest, e.g. they are both currently serving the interests of players in close proximity. The other is a subordinate interest where one computer's full set of interests is a small subset of the interests of another computer.
One can see that the computers with the most resources and greatest availability are not only most suited to superior positions in the hierarchy in terms of their ability to take responsibility for arbitration, but also in terms of their coverage and thus ability to service interests. It is therefore worth establishing relatively stable relationships between computers on this basis. We simply have the rule that every participating computer must have a parent, which then provides it with its only means of obtaining ownership of objects and primary means of obtaining ownership details of any other objects it may be interested in. Thus all computers can have a heuristic to select a parent based on how well it would be able to meet their interests in the long term, how good the communication with it is, and how reliable it is.
Given a computer's interests are likely to change over time, they may become so different from their fellow siblings that another parent may be better placed to satisfy them. After all, while a parent could gradually change its interests in line with the majority of its children, a child would obtain little benefit from its relationship if it quickly developed interests outside those of its parent - it would be better off obtaining a new parent that already had such an interest. With such changing conditions this parent selection process should be a continuous one.
By its nature the parent-child relationship would not be expected to change particularly frequently. A much more temporary relationship is the peer-to-peer one, where a computer will have determined that while it is not worth changing parent, it may well be worth forming a direct link with another computer in order to obtain the most up to date information possible regarding objects it's interested in. This would typically be the case when the other computer owned objects of interest. To locate suitable peers such as this a computer would express its interest to its parent who in servicing it would have provided information regarding which computers owned what. From this the child could determine whether it would be worth forming a peer relationship - it might not, if it would offer marginal or no benefit over the parental one.
Duties of Relationships
Rather than get bogged down by discussing the mechanisms and implications of all these interest based relationships, it's probably clearer simply to summarize them:
On behalf of the player
A parent must be selected that best meets the player's short-term needs. These include that it:
· holds a good proportion of the player's past, present, and future interests
· has low latency and generally good communication links
· is likely to be online, at least for the same duration as the player
· has good reliability statistics
The more objects that a parent (or its descendants) owns, the better.
The parent will be requested for updates to objects of interest, and implicit in this is a competitive request for ownership of any of those same objects.
The suitability of the parent over other candidates will be monitored fairly regularly and a new parent will be selected when the benefit of so doing outweighs the cost of change.
From information supplied by the parent, and in circumstances where updates are significantly more timely, peers owning objects of immediate interest will be requested for updates.
On behalf the parent
Objects to which a parent has granted ownership, become the responsibility of the computer until such time as ownership is relinquished to the parent. This applies even if the computer grants ownership to a child.
A careful record will be kept of objects to which ownership has been granted, and this responsibility must be carried on to any children to which ownership may be subsequently granted. Any changes in ownership, even between descendants, must be provided to the parent.
By default, changes made to any owned objects should be provided to the parent.
On behalf of its peers
Any changes to owned objects and updates to non-owned objects must be provided to peers that have expressed an interest in them. If ownership of objects changes, details should also be provided to interested peers.
On behalf of its children
The computer will adopt a child's interest and add it to its own. However, the children's interests are considered subordinate to those of the player.
Any changes to owned objects and updates to non-owned objects must be provided to children that have expressed an interest in them.
If one child appears to be a significantly more suitable owner of an object than oneself or any other child, then ownership is granted to that child.
On behalf of the system
The computer will adopt children on request, accept peer interests, monitor its integrity, and keep its parent informed regarding object state and ownership.
Relationships should be changed in a stable manner, e.g. incorporating hysteresis as appropriate.
Load Balancing
From the above we can see that there would be a continuous process of individual computers selfishly striving to achieve the most effective relationships possible. Out of this emerges the desired behavior of the entire system organizing and balancing itself in an optimal way. It will thus continually respond to change in demand, network performance, even adapting to variations in availability and reliability.
Simulation
Now that we have arrived at a method of ensuring computers tend to have the objects they need to satisfy the interests of their players, all that remains is to simulate them.
All that needs to be provided for this, is a means of processing the objects' behaviors. This would probably require the use of a virtual machine to process the encoded behaviors - this is best from a portability perspective. This would support a system of registering interest in local events and being able to raise events, generally an environment similar to that provided with some of the more sophisticated single-user games engines. This may also benefit from the inclusion of highly optimized, general purpose services such as collision detection, proximity analysis, etc.
Remember that some objects would be owned and some wouldn't. What this means in practice is that although all objects will be processed in the same way, the state of the non-owned objects will be overwritten at any time by an update of the 'true' state received from a peer or parent. However, given that the time of the update is known, its value should tend to coincide with the interpolation of the value currently computed. This is effectively 'dead reckoning': if we know an update value at time t, and compute a value for time t", then if we subsequently received a value for time t', we have a better value for time t"'.
So we can establish a continuous process of simulating a portion of the virtual world at the same time that it is continually being updated by information from owned objects. Another way of looking at it is that all computers share in the task of simulating all parts of the virtual world - by simulating the objects they're most qualified to, bearing in mind the amount of the virtual environment that they're able to contain and simulate. So, objects can be owned by the computers that are most appropriate to determine their 'true' state, and the heuristics must tend to ensure that such computers have a good proportion of the virtual world in which to provide a consensual environment for the objects they own. This allows the update to be regarded as a far better guide to the true state of an object - it's just time delayed (which can be compensated for).
Finally, only the objects matter, and only their state needs distributing. Of course, if some messages are defined that have significant importance, then perhaps they too may need to be distributed in some cases, e.g. it's no good sending a message to a mimic, if the message needed to get to the 'real' object. It's possible our system may need a method of forwarding messages in some circumstances, say if one object needed to modify the state of another directly, however this can be minimized. Events certainly don't need distributing, as they should be considered products of the local environment alone.
Low Integrity
The shoe is now on the other foot. Instead of the programmer being able to assume a reliable environment and require a system to go through hoops and great expense in achieving this, they must now assume an unreliable environment, thus relieving the system from this burden.
The programmer is in any case far better situated to know what matters and what doesn’t when designing objects. With objects being overwritten at any time, it is obviously important to design objects carefully so that they do not become confused by this.
Duplication is Better than Communication
One can see that with several computers potentially interested in the same areas of the virtual world, that much storage and processing is likely to be duplicated.
Rather than be wasteful redundancy, this is actually beneficial. It is far better to duplicate the simulation of objects you're interested in, and accept the 'true' values afterwards than to operate with out of date objects in the interim. This works on the principle that an object is typically autonomous and largely a product of its environment, so will behave similarly in similar environments. Thus latent updates should tend to be confirmatory as opposed to revelational.
The design decision we've already made, allows us such profligate processing: communication is always to be regarded as disproportionately more expensive than processing or storage.
One other area in which processing may be seen to be duplicated, is where in order to increase simulation fidelity the scene modeler will inevitably repeat a large amount of the simulation already performed for objects within a scene. As discussed earlier, this duplication is due to the separation that is necessary in order to ensure a common base standard of simulation. In any case, I would expect that processing devoted to higher fidelity scenery, would soon outweigh the processing used for the scene's standard simulation by at least an order of magnitude. In such a case there would be little to be gained by an attempt to let the scene modeler perform both functions. Nevertheless, there could be potential for the scene modeler to override the simulation of owned objects, thus allowing the extra fidelity to become available in a small way to the distributed simulation.
Making the Most of Available Resources
In spite of some duplicate use of resources, it is still important to make best use of what resources we have.
Nearly everything needs to be prioritized. This will be according to importance implicitly assigned to it by the player, peers and children (if any). The objects themselves are also likely to assign importance to various things, e.g. low detail texture or geometry may be given a greater importance than high detail ones. Some object behaviors may also be more important to process than others, e.g. an occasional blink of an eye may not be as important as walking.
The local database will typically be quite limited in size, so use of it must be restricted to those objects of most interest and importance.
When objects are transmitted it may be sensible to send them separately from any other information that they refer to (which can be assigned a lower importance).
Given the expense of communication it is important that steps be taken to ensure information at all levels is kept as compact as possible. There may even be an opportunity to use transparent compression methods when transmitting proprietary data, e.g. textures.
Secondary storage media should also be used where possible to avoid communicating some information across the network in the first place, e.g. CD-ROM (or better) can be used to store commonly used data, and could even contain low detail snapshots of popular parts of the virtual world. This way, even if someone visits somewhere they've not been before, at least some information is instantly available, and can be rapidly enhanced via the network.
Recovering from Failure
Let there be no doubt: the unreliability and failure tendency of networks and computer systems should be at the heart of any strategy to develop a large scale system on them. Just as the human brain is particularly resilient to local failure by virtue of its processing being distributed throughout its neurons, so the distributed systems approach can obtain similar tolerance to failure.
Because all computers contain ownership information for themselves and their descendants, there is always one side of a broken hierarchy that contains all ownership information. The broken branch will also have enough information to continue as though the break had not occurred. As soon as the break occurs the branch can assume that only its parent has failed and it can attempt to locate a grandparent or more distant ancestor.
Whatever the nature of the failure, there will eventually be a reconnection, and thus a reconciliation of object state. The only guideline needed here is that where arbitration is required when the branch reclaims ownership, it should not be in favor of the branch. Therefore malicious disconnection can be disadvantaged in the long run.
While it should be expected for the network to lose or delay messages, and computers to become unexpectedly disconnected from time to time, message and local database integrity should be assumed to be reliable. Measures will of course have to be taken to ensure this, however, they are unlikely to have a particularly large impact in performance terms. Checksums (or better) are a fraction of message size, and ensuring transactional integrity on local database operations is a minor task.
Inevitably, we must also take precautions against malicious or nefarious interference with the system. To some, this represents such a threat, that the very idea of a distributed systems approach is stillborn because of its dependence upon trust of each component computer (like putting automated teller machines in kids' bedrooms). Even if the security issue is seen as a major stumbling block, that should not hold back development of what is otherwise an eminently appropriate technology. The problem of assuring security and defense against malicious intent then becomes a secondary, technical one. Indeed, as long as most computers are reliable, or the remainder do not co-operate in their nefarious activities, it is not too arduous to perform a minor, background integrity-monitoring task - which can raise the alarm bells in the event of non-random integrity faults (including computational discrepancies) emanating from a particular computer or group.
Implementation
For simplicity it's probably best if each computer runs the same software, thus making the participating computers true peers, distinguished only by the resources they have at their disposal.
If the system is to be long lived, then so must the software it's built with. Naturally, software will need to be revised to discontinue particular features (bugs), but given the number of computers the system is expected to scale to, this revision will be arduous to administer unless it is completely automated. Although it is hoped that the software will not be particularly large, it would be prudent to divide it into fairly separate modules. Not only is modular software easier to revise, but it is easier to produce in the first place. Modular and Object Oriented Design methodologies are well suited to producing distributed systems.
An example of a suitable modular development system that is intended for global scale projects, is Microsoft's COM technology (component object model) which can be used in conjunction with their MTS (transaction server) and DNS (distributed network system/digital nervous system). This can handle network distribution of software components and can support automatic revision control.
STRATEGIC APPLICATION DESIGN
All we've been discussing so far, is really just the system, and the system is only half the story. The other half is actually using it to end up with the desired result, an application in other words.
Latency Persists
In spite of the best attempts to ameliorate the effects of latency by improving the underlying system, it will not disappear entirely. There is a physical limitation that prevents one user seeing another user's reaction to their action instantaneously if they are separated by a few thousand miles and several switching circuits. Until Star Trek gets a little closer to realization, the application designer will have to acquiesce and contrive to avoid or explain latency in some way.
It's surprising how many people think there is a technical solution to latency and that we'll all soon be playing international multiplayer twitch games as though connected via a global LAN. While we may well appear to end up playing such games (if the publisher's continue to consider this the market demand for the foreseeable future) they will behave with subtle differences to those played across a LAN (or not so subtly).
As I describe shortly, there are a variety of techniques which can be applied to application design in order to reduce the prominence of latency. Furthermore, these techniques are just as appropriate to highly optimized 16 player Internet games, as they are to large scale applications operating on distributed systems. In general they all revolve about the need to remove a player's expectation that they can interact directly with another distant player without latency.
Avoiding Encounters Between Players
Perhaps the crudest application design strategy, is simply to prevent distant players from meeting - if they can't meet, they can't notice latency. This strategy refines to one of reflecting the physical limitations of the real world in the virtual one. If players aren't in the same room (or LAN) in the real world, then how can they expect to be in the same room in the virtual one?
The application thus has to avoid (as opposed to forbid) distant players meeting. There's nearly always a way of making a feature out of a limitation. The player maybe restricted in travel, e.g. they're stranded on an iceberg or asteroid (strangely having a geographical correspondence) and may deal direct with other’s envoys, or may issue their own envoys, but player may only meet player if proximity allows (both players are on the same LAN, say).
This technique allows us to still have a twitch game, but the game must conspire to prevent avatars controlled by distant players from meeting.
Separating the Player from the Avatar
A slightly more subtle trick is to avoid allowing the player to think that they exist in the virtual world in the first place. If players don't exist in the virtual world then they can't meet there. Instead, of the player being there, they are entrusted with the control of a denizen of the virtual world, an 'avatar' in the vernacular. The avatar is the player's representative to which the player delegates control, to a lesser or greater extent.
If considered separately in this way, the avatar’s body does not necessarily map to the player’s. This is perhaps the most significant means of escaping the 'twitch' legacy. The puppetry of twitch games requires the player to be one with the puppet, whereas a largely autonomous avatar may be influenced to a degree determined by the prevailing latency.
A player may still be entertained if their interactive control does not obtain instantaneous response (as distinct from interface feedback) - as long as their expectations are managed, i.e. they are not encouraged to identify with their avatar. For example, the player as a coach may suggest an upper hook, for his avatar boxer to perform at the next opportunity – the boxer may not hear, of course. Thus the direct linkage of 'control' degrades subtly to a less guaranteed 'influence'.
Delegating Control
Following on from the method of separating the player from their virtual presence, their avatar, one can see that delegation can play a much larger role than it has in games so far. Indeed, its credentials as the preferred solution to latency stretch way back throughout mankind's history - particularly warfare. When delays in orders being carried out, and reports of their effects, are measured in flight times of carrier pigeons, then delegation is the best option for all but the highest level of commands.
In terms of application design this technique would manifest itself as players entrusting other avatars than their own to carry out their wishes where latency prohibits a direct presence. These other avatars could either be independent automatons or controlled by other players.
We already see in many real-time strategy games the act of fighting being delegated to the player's minions. Though, as excellently demonstrated in Dungeon Keeper[3], the player is sometimes allowed to resume responsibility for a particular character's combat should the player consider it warranted.
Incorporating Latency
Of course, latency is only a problem where it is of longer duration than the delay between initiating an event and the event occurring. There are thus some circumstances where latency is not a problem, e.g. when steering an oil-tanker or firing a torpedo. The result of ones manipulation of controls in these cases is expected to be delayed.
There is scope for some games where while nearly all interaction between player's avatar and its environment is visible only to the player, the only effects significant to other players can be delayed from their initiation, thus largely immune to latency. Imagine a game called 'Galleon' or 'Armada' for example, where groups of LAN based players, could crew one or more galleons per LAN (with computer controlled avatars taking up any slack). As far as each player is concerned, the wheel at the helm rotates immediately and the fuses light immediately. However, the heading changes gradually, and the fuses take time to burn before the cannons fire. Thus interaction between potentially distant crews (LANs) across the Internet is subject to intrinsic delay and so can incorporate latency.
Of course, this is a contrived example, but then it intends to demonstrate that one can successfully contrive to incorporate latency in the behavior of the virtual world.
Plans, Policies, and Predictions
Extending upon the idea of intrinsically delayed commands, one can see that sequences of such commands would be even better at masking latency.
If ever there is an occasion for a player to obtain advantage from a plan of their actions in the virtual world, whether via an avatar or some other device, then it is a good case for the instituting of a means whereby the player can express this plan. If this plan once committed can be published for use in the distributed simulation (other players won't see it - only its execution) then the player's actions effectively become local to each witness. Perhaps an example of player plans is in the game of American football, or in the programming of evasive maneuvers of a starship.
More sophisticated than plans are policies. Implemented as small programs, these are likely to be useful for the player as a means of expressing contingent instructions to their avatars for occasions when the player is separated from them or latency prevents timely receipt of the player's commands. If avatars carry these policies with them, then it is one step towards embodying the avatar with the player's personality - who can tell the difference between a clone and the player?
One variant on a plan that is worth a mention is a prediction. This is simply a plan that has been extrapolated from previous behavior. With processing power to spare it may be possible to analyze a player's behavior (from their avatar) and arrive at a more sophisticated and thus more human model of the player than their avatar alone.
The bottom line is that until one receives confirmation of a player's true actions, anything that provides a good prediction of it in the interim is better than nothing. Sometimes, when the player becomes disconnected, this prediction may be taken as gospel (ownership of the player's avatar will default elsewhere).
Hiding Effect from Cause
One small trick, but none the less for its utility, is to imply immediate effect of an action, but to mask the precise effect until later or an accumulation becomes significant. This allows enough time for the eventual reaction to be agreed upon.
An example of this is the damage suffered between opponent players in a spaceship battle. Each hit may cause immediate damage, but in a nonspecific, non-critical sense. There may be explosions masking the hulls of each other's craft, thus delaying confirmation of precise damage until the explosions have died down. Which player is the eventual winner, can be determined according to who had the greatest accumulation of hits.
The utility of this technique only begins to come clear when you consider that one player may take evasive action prior to destruction. You need a grace period in which to determine a battle's outcome, so that if it turns out that there is a disagreement in whether one player escaped or got destroyed, the resolution is acceptable rather than obviously wrong. The player is unlikely to be upset if a ship with 35 hits manages to escape destruction when it should have exploded at 32. Whereas, a ship that explodes to destruction on a single hit, but manages to escape, is patently unacceptable.
Acceptance and Explanation
There are occasions when latency is so severe, or arises without warning, that it becomes blatantly visible and impossible to mask or avoid. In such cases the only recourse is to have a similarly unpredictable phenomenon arising in the virtual world, or a means of expressing the presence of latency, but without it grating against the context of the virtual world.
One could play on the god like separation of player from avatar, by introducing a mist or fog across the scene at times when the player's avatar was traveling in distant lands and latency became particularly bad. Alternatively one could indicate that the player's avatar had developed a temporary deafness, or was intermittently prone to seizures of indecision.
As long as the player is not identified with the avatar, it is possible to explain away communication problems. Indeed, the player may be quite prepared for the avatar to need a large degree of autonomy at particularly difficult times.
The other side of the coin in terms of latency's effects, is what happens when the true state of an object overrides the current object state, and is radically different from it. The only solution is to avoid this happening in the first place. In the case of low latency conditions there's little problem, but in the case of unexpected delay or in process of reconciliation after a sustained disconnection, there will be a glitch, or discontinuity as one state changes to another. There is no magic solution. Our entire strategy so far has been to accept this hazard, because the only alternative is to slow the whole world down until there's perfect agreement. The only thing to do is flash a puff of smoke, turn out the lights, move the scenery and actors to their correct places, and continue. Some might argue that it would be better to fix the world with the lights on, so to speak. If an actor is in the wrong place, do you get them to race to the correct position, teleport them there, or leave them in the wrong position only for more peculiar behavior to develop? This is one of the more intractable problems and really can only be addressed by the applications designer. The application has to conspire to make this such a rare occurrence that its remedy, as unsightly as it is, is tolerable.
Preventing Conflict from Escalating
Sod's law now comes into play - whatever can go wrong probably will. There will be reconciliations that will result in ridiculous, impossible, or paradoxical situations. An avatar may find a car in their pocket, but worse, discover that it's the car they're currently driving. This is just a wild suggestion, not to be taken as an indication of intrinsic flakiness in the system, but that the application should really survive such a compromise to its integrity.
There will be techniques of designing the application, the virtual world, both at high levels and in programming terms so that such impossible situations do not tend to happen, or if they do they rapidly dissolve into more sensible arrangements. One of the key differences to a conventional programming environment in this case is that the assumption of reliability and integrity is replaced by the converse. Nearly all objects will have to be largely autonomous, continuously observing the rules of their virtual environment and reevaluating their situation and relationships.
A consequence of the potential for inconsistent scene state is that there is a risk of it escalating, at least if the measures taken against it are inadequate. An object being in the wrong place may trigger one chain of events that conflicts with the chain of events set off by the object in its correct place. If the virtual world is not able to absorb such inconsistencies, then they may escalate with disastrous results.
I suspect that there will be a large degree of inertia in the software engineering industry to prefer reliable operating environments, thus dismissing the communications benefits obtained from sacrificing integrity. However, in spite of the additional burden programmers of virtual worlds will face in coping with latency and unreliability, their efforts will be rewarded a million-fold, given the players that will enjoy living in them.
Commerce
We have arrived at a new kind of system, one that will brook a new kind of financial relationship. Everyone that participates may contribute as well as consume - both content and resources. In spite of most player's balances likely to turn out at a loss, the system can still be equitable, and be seen to be so.
Let's say that all users were micro-charged in proportion to the content they viewed and resources they consumed, but were given content creation tools and the means to provide their resources to others. If this micro-royalty went directly to the content author or resource provider, we'd probably end up with an even more attractive remuneration scheme than exists on the Web at present.
It has to be admitted however, that although charging on volume of content may be equitable, it is not necessarily the most user-friendly pricing mechanism. Even so, this does not preclude the more popular subscription pricing mechanism, it simply requires extra calculation in allocating subscription income to royalties.
Under this scheme, participation (in the form of providing resources) should then become attractive to Internet service providers, and other facilities with otherwise unused computing resources. These can be supplied to the system for a competitive fee.
While a system of fixed prices could be used initially, there would be potential to adopt a free market based system with each computer pricing its resources as it saw fit, and specifying a maximum price that it would buy. Then again, perhaps we're moving towards an enlightened civilization where our labors in Cyberspace are largely philanthropic.
When you consider just how large scale an endeavor it is to create a virtual world, let alone several, you begin to realize that like the Web, you may need a large proportion of the users to create the content before you have a product. Hopefully, Cyberspace, just like the Web, will snowball.
Conclusion
I hope I have convinced you of the need for a scalable and ‘best-effort’ distributed systems approach if we are to build solid and lasting foundations for cyberspace, and moreover, soon to enjoy interactive entertainment on an epic scale.
Above all, we must not become hamstrung by the requirement for perfect synchrony. The very low latency which it requires, will always be the preserve of theme parks and dedicated networks. Beware of road-builders’ claims that traffic jams will soon be a thing of the past.
To have suggested that we abandon consistency, integrity and synchrony as primary goals, relegating them as welcome side-effects, focusing instead on scalable and best-effort techniques may be regarded as radical by some, and perhaps by others as not radical enough. Either way, we should not wait for a time when conditions are ‘good enough’ for a perfectly synchronized virtual world, for that is the prevarication of skeptics. There would never be such a time. If we know things will get better, why not start today, building a system that will take advantage of better times tomorrow?
Acknowledgements
I would like to express thanks to Pepper’s Ghost Productions for funding this paper, to Sir Peter Michael for his astuteness, and to Karen & Godfrey Parkin for thinking ‘large scale’.
Bibliography
Coulouris, George, et al. Distributed Systems: Concepts and Design, 2nd ed. Harlow, England: Addison-Wesley Publishing Co., 1994.
Dodsworth Jr, Clark. Digital Illusion: Entertaining the Future with High Technology. New York: ACM Press, 1998.
Singhal, Sandeep; Zyda, Michael. Networked Virtual Environments: Design and Implementation. Harlow, England: Addison-Wesley Publishing Co., 1999.
References
[2] P. Freund, and G. Martin. The Ecology of the Automobile. Black Rose Books, Montreal, page 7, 1993.
[4] P. Hobermann. Storytelling after cinema II. In Proc. ACM Multimedia'96, Nov 1996.